![[Adlam Sample Image]](http://www.unicode.org/announcements/new-repertoire-5cd.jpg "Adlam Sample Image")
Mountain View, CA, USA – The Unicode® Consortium today announced the start of
the beta review for the forthcoming Unicode 9.0.0, which is scheduled for
release in June, 2016. All beta feedback must be submitted by May 2, 2016.
Unicode is the foundation for all modern software and communications around
the world, including all modern operating systems, browsers, laptops, and smart
phones – plus the Internet and Web (URLs, HTML, XML, CSS, JSON, etc.). Thus it
is important to ensure a smooth transition to each new version of the Unicode
Standard.
Unicode 9.0.0 comprises several additions and changes which require careful
migration in implementations. These include asymmetric case mappings, numerous
variation sequences, new fractional numeric values, and changes to property
values, especially East_Asian_Width values. The line breaking and text
segmentation algorithms handle character sequences that represent emoji as
indivisible units via the addition of new property values and rules.
Implementers need to modify code and check assumptions for all affected
processes to support these additions and changes.
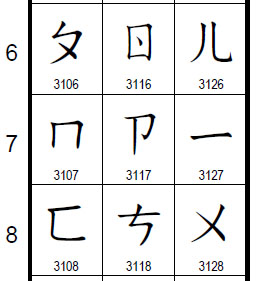
The new character repertoire includes 74 emoji symbols, 19 symbols used in
Japanese TV broadcasting, and multiple additions to existing scripts. There are
six new scripts, of which three are in modern use (Adlam, Osage, and Newa) and
three are historic (Bhaiksuki, Marchen, and Tangut). Adlam and Osage have case
pairs and require data updates for casing functions. Tangut is a large
ideographic script whose addition incurred changes to the Unicode Collation
Algorithm (used as the basis for sorting text in all languages).
Please review the documentation, adjust your code, test the data files, and
report errors and other issues to the Unicode Consortium by May 2, 2016.
Feedback instructions are on the beta page.
See
http://unicode.org/versions/beta-9.0.0.html
for more information about testing the 9.0.0 beta.
See
http://unicode.org/versions/Unicode9.0.0/
for the current draft summary of Unicode 9.0.0.
About the Unicode Consortium
The Unicode Consortium is a non-profit organization founded to develop,
extend and promote use of the Unicode Standard and related globalization
standards. The membership of the consortium represents a broad spectrum of
corporations and organizations, many in the computer and information processing
industry. Members include: Adobe, Apple, Emoji One, EmojiXpress, Facebook,
Google, Government of Bangladesh, Government of India, Huawei, IBM, Microsoft,
Monotype Imaging, Sultanate of Oman MARA, Oracle, SAP, Tamil Virtual University,
The University of California (Berkeley), Yahoo!, plus well over a hundred
Associate, Liaison, and Individual members. For more information, please contact
the Unicode Consortium
http://www.unicode.org/contacts.html.
 The
Adopt-a-Character program has awarded a grant to support further development
of the following four Indic scripts in the Unicode Standard:
The
Adopt-a-Character program has awarded a grant to support further development
of the following four Indic scripts in the Unicode Standard: A proposed update of
A proposed update of  This holiday season you can give a unique gift by adopting any emoji, letter, or symbol — and help support the Unicode Consortium’s mission to enable all languages to be used on computers. Three levels of sponsorship are available, starting at $100. With over 128,000 characters to choose from, you are certain to find an appropriate character, for even the most demanding recipient. All sponsors will receive a custom digital badge featuring the adopted character for use on the web and elsewhere. Sponsors at the two highest levels will receive a special thank-you gift engraved with the name you supply and the adopted character.
This holiday season you can give a unique gift by adopting any emoji, letter, or symbol — and help support the Unicode Consortium’s mission to enable all languages to be used on computers. Three levels of sponsorship are available, starting at $100. With over 128,000 characters to choose from, you are certain to find an appropriate character, for even the most demanding recipient. All sponsors will receive a custom digital badge featuring the adopted character for use on the web and elsewhere. Sponsors at the two highest levels will receive a special thank-you gift engraved with the name you supply and the adopted character.
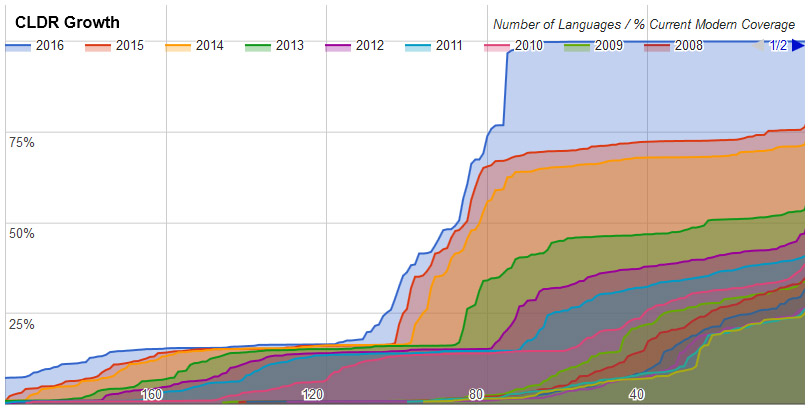
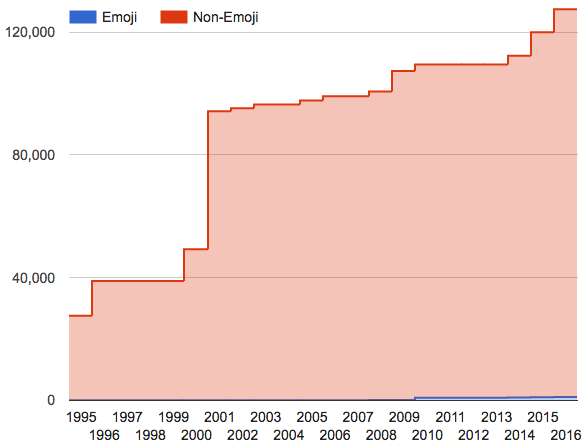
![[hourglasses]](http://www.unicode.org/announcements/hourglasses.png "hourglasses")
![[Unicode 9.0 Cover Art]](http://www.unicode.org/announcements/uni90-pod-front.jpg "Unicode 9.0 Cover Art") The Unicode 9.0 core specification is now available in paperback book form with a new, original cover design. This edition consists of a pair of modestly priced print-on-demand volumes containing the complete text of the core specification of Version 9.0 of the Unicode Standard.
The Unicode 9.0 core specification is now available in paperback book form with a new, original cover design. This edition consists of a pair of modestly priced print-on-demand volumes containing the complete text of the core specification of Version 9.0 of the Unicode Standard.![[Myanmar Glyphs]](http://www.unicode.org/faq/unicode_text_in_unicode.png "Myanmar Glyphs") A new FAQ on
A new FAQ on 
![[doctor emoji]](http://www.unicode.org/announcements/doctor-emoji.png "doctor emoji") A proposed update of
A proposed update of ![[cover art by Gabee Ayres]](http://www.unicode.org/announcements/TUS9-Ayres-375px.jpg "cover art by Gabee Ayres")
![[Jiachen Hu]](http://www.unicode.org/announcements/TUS9-JiachenHu-200px.jpg "submission by Jiachen Hu")
![[Laura von Husen]](http://www.unicode.org/announcements/TUS9-LauraVonHusen-200px.jpg "submission by Laura von Husen")
![[cover art]](http://www.unicode.org/announcements/tus90-cover-thumb.png "cover art") The core specification for Version 9.0 of the Unicode Standard is now available, containing significant updates and improvements, including descriptions for six new scripts, 72 new emoji characters, and 19 symbols for the new 4K TV standard.
The core specification for Version 9.0 of the Unicode Standard is now available, containing significant updates and improvements, including descriptions for six new scripts, 72 new emoji characters, and 19 symbols for the new 4K TV standard.![[cartouche]](http://www.unicode.org/announcements/cartouche.png "cartouche") The
The  Version 9.0 of the Unicode Standard is now available. Version 9.0 adds exactly 7,500 characters, for a total of 128,172 characters. These additions include six new scripts and 72 new emoji characters.
Version 9.0 of the Unicode Standard is now available. Version 9.0 adds exactly 7,500 characters, for a total of 128,172 characters. These additions include six new scripts and 72 new emoji characters.








![[Emoji image]](http://www.unicode.org/announcements/owl_1f989.png "U+1F989 OWL") The Unicode Consortium’s
The Unicode Consortium’s  (shrug),
(shrug),
 (face
palm),
(face
palm), (bacon),
and 68 others. The funds help the consortium’s work of supporting the world’s
languages in digital form.
(bacon),
and 68 others. The funds help the consortium’s work of supporting the world’s
languages in digital form.![[Emoji Image]](http://unicode.org/announcements/android_1f926.png) The 72 new emoji characters for Unicode 9.0 are now final, and listed in
The 72 new emoji characters for Unicode 9.0 are now final, and listed in ![[Mayan Image]](http://www.unicode.org/announcements/mayan-annc.jpg)

![[cover1]](http://www.unicode.org/announcements/u90call/TUS-7-Vols1-and-2-400px.jpg)
![[IUC 40 Banner]](http://www.unicodeconference.org/_borders/main-2016.jpg)
![[female runner image]](http://www.unicode.org/announcements/female-runner.jpg) Unicode emoji characters are specified by UTR #51, Unicode Emoji and
its related data files. Now available for public review and comment are a
proposed update of UTR #51, plus a draft of a related new document,
UTS
#52, Unicode Emoji Mechanisms.
Unicode emoji characters are specified by UTR #51, Unicode Emoji and
its related data files. Now available for public review and comment are a
proposed update of UTR #51, plus a draft of a related new document,
UTS
#52, Unicode Emoji Mechanisms.