
Since its founding, the Unicode Consortium has grown and expanded its charter and scope. We’re embarking on a new chapter in the evolution of the Consortium and are pleased to announce the appointment of Toral Cowieson in the newly-created position of Executive Director & COO.
“We are thrilled to have Toral joining the team,” said Mark Davis, President and cofounder of the Consortium. “She brings a wealth of experience in leadership across non-profits, corporations, and board service. Her recent time at the Internet Society, including as head of Strategy and Impact Measurement, puts Unicode in good stead for this next stage of growth."
In this senior executive position reporting to the Chair of the Board of Directors, Ms. Cowieson will collaborate with the Board, officers, and team to extend the technical mission and impact, set the future agenda and program priorities, and ensure the long-term health and sustainability of the organization.
“Unicode standards are at the heart of how users seamlessly receive and share information across the nearly 22 billion devices around the world. I’m honored and excited to be joining the Consortium at this juncture, and look forward to working with the Board, staff, and the extended Unicode community to advance the mission and have an even greater impact in the years to come,” commented Ms. Cowieson.
In addition to Ms. Cowieson joining as Executive Director, the Consortium is also pleased to announce the following changes:
Board and Other Leadership Updates
Iris Orriss, who joined the Unicode Board in 2019, has been elected as the Treasurer of the Consortium. She is VP of Internationalization, Product Quality, and Product Experience Analytics at Facebook. Ms. Orriss is also Chair of the Board’s Finance and Funding Committee.
Greg Welch, member of the Board since 2013, has been elected as the Secretary of the Consortium and carries forward the excellent work done in this office by Michel Suignard for more than a decade. Mr. Welch is also Chair of the Board’s Governance & Nominating Committee.
Markus Scherer, the Chair of the ICU Technical Committee, has been appointed a Vice President. He is a member of the Google software internationalization team, focusing on the effective use of Unicode and on the development and deployment of cross-product internationalization libraries.
Announcing Unicode Fellows
The Consortium has recently created a new category for distinguished contributors, whose deep, long-term knowledge of internationalization and dedication to work on standards has greatly benefited the Consortium for many years. The Consortium is pleased to announce its two inaugural Unicode Fellows.
Peter Edberg has been named a Unicode Fellow. He has worked on internationalization, text and language support at Apple since 1988. He has been Apple’s representative to the Consortium for many years, and has been actively involved since 2008 with the Unicode CLDR and ICU projects.
Michel Suignard has been named a Unicode Fellow after serving as Secretary for the Unicode Consortium from 2007 to 2020. He worked for more than twenty-five years at Microsoft, where he held various positions in the development and sales divisions, many involving the development of the Unicode Standard. He is currently an independent consultant working on character encoding related matters, such as Internationalized Domain Names (IDN) and typography. Michel is the code chart editor for the Unicode Standard and is also the project editor of ISO/IEC 10646, which is the ISO standard aligned with the Unicode Standard.
Over 140,000 characters are available for adoption
to help the Unicode Consortium’s work on digitally disadvantaged languages
![[badge]](https://www.unicode.org/announcements/ynh-infinity.png)


![[nest image]](https://www.unicode.org/announcements/nest-with-blue-eggs-128px.png)
![[beta image]](https://www.unicode.org/announcements/cldr40-alpha-annc.png)
 Version 14.0 of the Unicode Standard is now available, including the core specification,
annexes, and data files. This version adds 838 characters, for a total of 144,697
characters. These additions include five new scripts, for a total of 159
scripts, as well as 37 new emoji characters.
Version 14.0 of the Unicode Standard is now available, including the core specification,
annexes, and data files. This version adds 838 characters, for a total of 144,697
characters. These additions include five new scripts, for a total of 159
scripts, as well as 37 new emoji characters.![[badge]](https://www.unicode.org/announcements/ynh-1fab4-potted-plant.png)
![[badge]](http://www.unicode.org/announcements/ynh-infinity.png)





 This week, the Unicode Consortium is excited to celebrate the calendar emoji, 📅,
commonly displayed with July 17th. People are the power driving the popularity
of emoji through their innovative use of them to share joy, activities, sports,
individuality, and so much more.
This week, the Unicode Consortium is excited to celebrate the calendar emoji, 📅,
commonly displayed with July 17th. People are the power driving the popularity
of emoji through their innovative use of them to share joy, activities, sports,
individuality, and so much more. The beta review period for Unicode 14.0 has started. The Unicode Standard is the foundation for all modern software and communications around the world, including all modern operating systems, browsers, laptops, and smart phones-plus the Internet and Web (URLs, HTML, XML, CSS, JSON, etc.). The Unicode Standard, its associated standards, and data form the foundation for CLDR and ICU releases. Thus it is important to ensure a smooth transition to each new version of the standard.
The beta review period for Unicode 14.0 has started. The Unicode Standard is the foundation for all modern software and communications around the world, including all modern operating systems, browsers, laptops, and smart phones-plus the Internet and Web (URLs, HTML, XML, CSS, JSON, etc.). The Unicode Standard, its associated standards, and data form the foundation for CLDR and ICU releases. Thus it is important to ensure a smooth transition to each new version of the standard.
![[cover1]](https://www.unicode.org/announcements/u14call/annc-v13-cover-huijun-shan.jpg)
![[hands image]](https://www.unicode.org/announcements/hands-waving-annc.png)
![[crane image]](https://www.unicode.org/announcements/cldr-39-annc-crane.png)
![[beta image]](https://www.unicode.org/announcements/large-beta-green.png)
![[badge]](http://www.unicode.org/announcements/ynh-eye.png)
 The Unicode CLDR v39 Alpha is now available for testing. The alpha has already
been integrated into the development version of ICU. While the scope of the
changes is small in this cycle, there are some significant migration issues, so
we would especially appreciate feedback from non-ICU consumers of CLDR data.
Feedback can be filed at
The Unicode CLDR v39 Alpha is now available for testing. The alpha has already
been integrated into the development version of ICU. While the scope of the
changes is small in this cycle, there are some significant migration issues, so
we would especially appreciate feedback from non-ICU consumers of CLDR data.
Feedback can be filed at
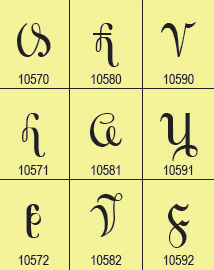
 The repertoire for Unicode 14.0 is now open for early review and comment. During alpha review the repertoire is reasonably mature and stable, but is not yet completely locked down. Discussion regarding whether certain characters should be removed from the repertoire for publication is welcome. Character names and code point assignments are reasonably firm, but suggestions for improvement may still be entertained.
The repertoire for Unicode 14.0 is now open for early review and comment. During alpha review the repertoire is reasonably mature and stable, but is not yet completely locked down. Discussion regarding whether certain characters should be removed from the repertoire for publication is welcome. Character names and code point assignments are reasonably firm, but suggestions for improvement may still be entertained. A
A 
