 The Unicode Consortium is pleased to announce the release of the 2017-12-12 version of the Unicode Ideographic Variation Database (IVD), which is the sixth version, and includes five registered collections. This version registers the new KRName collection and the first 36 sequences in that collection, four additional sequences in the registered Adobe-Japan1 collection, and 674 additional sequences in the registered Moji_Joho collection. Details can be found on the main IVD page.
The Unicode Consortium is pleased to announce the release of the 2017-12-12 version of the Unicode Ideographic Variation Database (IVD), which is the sixth version, and includes five registered collections. This version registers the new KRName collection and the first 36 sequences in that collection, four additional sequences in the registered Adobe-Japan1 collection, and 674 additional sequences in the registered Moji_Joho collection. Details can be found on the main IVD page.
Tuesday, December 12, 2017
New version of Unicode Ideographic Variation Database released
The Unicode Consortium is pleased to announce the release of the 2017-12-12 version of the Unicode Ideographic Variation Database (IVD), which is the sixth version, and includes five registered collections. This version registers the new KRName collection and the first 36 sequences in that collection, four additional sequences in the registered Adobe-Japan1 collection, and 674 additional sequences in the registered Moji_Joho collection. Details can be found on the main IVD page.
Monday, December 11, 2017
Feedback on Draft additional repertoire for ISO/IEC 10646:2017 (5th edition) DAM1 and PDAM2.2
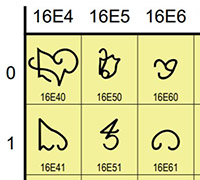 The Unicode Technical Committee is soliciting feedback on pending additions
to the draft repertoire of characters, to help discover any errors in character
names, incorrect glyphs, or other problems. There is a short window of
opportunity to review and comment on the repertoire additions noted below.
The Unicode Technical Committee is soliciting feedback on pending additions
to the draft repertoire of characters, to help discover any errors in character
names, incorrect glyphs, or other problems. There is a short window of
opportunity to review and comment on the repertoire additions noted below.The following additional repertoires from ISO/IEC 10646:2017 (5th Edition), which are in ballot, and are under review. See the associated repertoires in: Draft additional repertoire for ISO/IEC 10646:2017 (5th edition) DAM1 [PRI #366] and PDAM 2.2 [PRI #365].
The Unicode Standard is developed in synchrony with ISO/IEC 10646. Note that for DAM1, no further changes or corrections will be possible after ISO balloting is completed. Comments the PDAM 2.2 repertoire can be made on later ballots. (See the FAQ Standards Developing Organizations for additional information on the stages in ISO standards development.) Advance feedback on these repertoire additions will help inform the UTC discussions about its own contribution to the ISO balloting process.
Documents referenced in the draft repertoire with numbers such as L2/17-372 (DAM1) and L2/17-366 (PDAM 2.2) are available in the UTC Document Registry.
For information about how to discuss these Public Review Issues and how to supply formal feedback, please see the feedback and discussion instructions.
Wednesday, December 6, 2017
Support Unicode with an Adopt-a-Character Gift this Holiday Season!
 This holiday season you can give a unique gift by adopting any emoji,
letter, or symbol — and help support the Unicode Consortium’s mission to
enable all languages to be used on computers. Three levels of sponsorship
are available, starting at $100. With over 130,000 characters to choose
from, you are certain to find an appropriate character, for even the most
demanding recipient. All sponsors will receive a custom digital badge
featuring the adopted character for use on the web and elsewhere. Sponsors
at the two highest levels will receive a special thank-you gift engraved
with the name you supply and the adopted character.
This holiday season you can give a unique gift by adopting any emoji,
letter, or symbol — and help support the Unicode Consortium’s mission to
enable all languages to be used on computers. Three levels of sponsorship
are available, starting at $100. With over 130,000 characters to choose
from, you are certain to find an appropriate character, for even the most
demanding recipient. All sponsors will receive a custom digital badge
featuring the adopted character for use on the web and elsewhere. Sponsors
at the two highest levels will receive a special thank-you gift engraved
with the name you supply and the adopted character.The program funds work on “digitally disadvantaged” languages, both modern and historic. In 2017 the program awarded grants to support work on Mayan hieroglyphs and historic Indic scripts, among others.
To date, the Adopt-a-Character program has had over 500 sponsors. Be part of the next wave, with a worthwhile gift!
For more information on the program, or to adopt a character, see the Adopt-a-Character Page.
Monday, December 4, 2017
Unicode Emoji 11.0 Beta
Emoji 11.0 beta is now available for developers, with 130 Draft Candidates, such as:







The list is not final: changes can include removals or additions: for example, new ZWJ sequences could be added. The decisions of the 2017Q4 UTC meeting for emoji have been incorporated into the draft Charts, Specification, and Data, and are now available for testing and feedback. The contents will be finalized in 2018Q1. The following are the expected dates for 2018.
The version number for the next release of Unicode emoji is jumping from the previously-released Emoji 5.0 to Emoji 11.0 (instead of 6.0). This is due to alignment of the emoji versions in 2018 and beyond with the versions of the Unicode Standard.
The draft emoji 11.0β Charts now show the candidates in context: for example, Emoji Ordering, v11.0β shows the sorting of all the emoji, with the candidates highlighted with rounded-rectangles. Feedback on the sort-order, categories, names, and keywords is welcome.
The draft 11.0β Specification has a number of changes, including proposed guidelines for display, handling gender, handling skin tone, and a proposed mechanism for allowing emoji to point either to the right or left.
The draft 11.0β Emoji Data provides property data, which determines how implementations handle the new characters.
The list is not final: changes can include removals or additions: for example, new ZWJ sequences could be added. The decisions of the 2017Q4 UTC meeting for emoji have been incorporated into the draft Charts, Specification, and Data, and are now available for testing and feedback. The contents will be finalized in 2018Q1. The following are the expected dates for 2018.
| Emoji Set | Decision date | Announcement of final list | Market availability |
| Draft Emoji Candidates (2018) | 2018-01 | 2018-03 | 2018H2 |
The version number for the next release of Unicode emoji is jumping from the previously-released Emoji 5.0 to Emoji 11.0 (instead of 6.0). This is due to alignment of the emoji versions in 2018 and beyond with the versions of the Unicode Standard.
The draft emoji 11.0β Charts now show the candidates in context: for example, Emoji Ordering, v11.0β shows the sorting of all the emoji, with the candidates highlighted with rounded-rectangles. Feedback on the sort-order, categories, names, and keywords is welcome.
The draft 11.0β Specification has a number of changes, including proposed guidelines for display, handling gender, handling skin tone, and a proposed mechanism for allowing emoji to point either to the right or left.
The draft 11.0β Emoji Data provides property data, which determines how implementations handle the new characters.
Over 130,000 characters are available for adoption, to
help the Unicode Consortium’s work on digitally disadvantaged languages.
![[fortune cookie badge]](http://www.unicode.org/announcements/ynh-fortune-cookie.png)
Wednesday, November 1, 2017
CLDR Version 32 Released
 Unicode CLDR 32 provides an update to the key building blocks for software supporting the world’s languages. This data is used by all major software systems for their software internationalization and localization, adapting software to the conventions of different languages for such common software tasks.
Unicode CLDR 32 provides an update to the key building blocks for software supporting the world’s languages. This data is used by all major software systems for their software internationalization and localization, adapting software to the conventions of different languages for such common software tasks.Some of the improvements in the release are:
- More complete data
- Major contributions of main locale data for Chakma (ccp), Sindhi (sd), Odia (or), Kabyle (kab), Pashto (ps), Turkmen (tk), Norwegian Nynorsk (nn), Assamese (as), and others.
- Rule-based number formats for Indian English, Akan, Hindi (oblique), Cherokee; revisions to some others.
- Import of draft subdivision names and language groups from wikidata.
- New data types
- Numeric exemplars. For example, in zh: [\- , . % ‰ + 0 1 2 3 4 5 6 7 8 9 〇 一 七 三 九 二 五 八 六 四]
- “Disjunctive” list style (eg “a, b, or c”)
- AvailableFormats items for day periods (skeleton “
Bhm”→ pattern “h:mm B” → “1:30 in the afternoon”)
- Major additions for Emoji
- Emoji name and keyword updates for Unicode 10 and Emoji 5.0 (minor updates for English, full data collection for other languages). Keywords now in sorted order.
- Adjustments to emoji collation
ICU 60 Released
ICU 60 upgrades to Unicode 10 and CLDR 32, and ICU4J has been tested with Java 9. ICU 60 includes a new API for number formatting. There are many more features and bug fixes.
For details please see http://site.icu-project.org/download/60
Tuesday, October 31, 2017
Graphemics in the 21st Century Conference
![[graphematik image]](http://www.unicode.org/announcements/graphematic.jpg "graphematik") The Unicode Consortium is pleased to announce a conference that may be of interest to our user community.
The Unicode Consortium is pleased to announce a conference that may be of interest to our user community./gʁafematik/ 2018 is the first conference bringing together disciplines concerned with writing systems and their representation in written communication. The conference aims to reflect on the current state of research in the area, and on the role that writing and writing systems play in neighboring disciplines like computer science and information technology, communication, typography, psychology, and pedagogy. In particular it aims to study the effect of the growing importance of Unicode with regard to the future of reading and writing in human societies. Reflecting the richness of perspectives on writing systems, /gʁafematik/ is actively interdisciplinary, and welcomes proposals from researchers from the fields of computer science and information technology, linguistics, communication, pedagogy, psychology, history, and the social sciences.
/gʁafematik/ aims to create a space for the discussion of the range of approaches to writing systems, and specifically to bridge approaches in linguistics, informatics, and other fields. It will provide a forum for explorations in terminology, methodology, and theoretical approaches relating to the delineation of an emerging interdisciplinary area of research that intersects with intense activity in practical implementations of writing systems.
The conference will be held at IMT Atlantique (formerly Télécom Bretagne) at Brest, France, on June 14-16, 2018.
Topics will include:
- Epistemology of graphemics: history, onomastics, topics, interaction with other disciplines
- Foundations of graphemics
- History and typology of writing systems, comparative graphemics
- Semiotics of writing and of writing systems
- Computational/formal graphemics
- Graphemic theory of Unicode encoding
http://conferences.telecom-bretagne.eu/grafematik/
https://twitter.com/grafematik2018e
Friday, October 13, 2017
New Gold Sponsor comprigo
The Unicode Consortium is pleased to announce that comprigo is now a gold sponsor for:
 comprigo's sponsorship directly funds the work of the Unicode Consortium in enabling modern software and computing systems to support the widest range of human languages. There are approximately 7,000 living human languages. Fewer than 100 of these languages are well-supported on computers, mobile phones, and other devices. AAC donations are used to improve support for digitally disadvantaged languages, and to help preserve the world’s linguistic heritage.
comprigo's sponsorship directly funds the work of the Unicode Consortium in enabling modern software and computing systems to support the widest range of human languages. There are approximately 7,000 living human languages. Fewer than 100 of these languages are well-supported on computers, mobile phones, and other devices. AAC donations are used to improve support for digitally disadvantaged languages, and to help preserve the world’s linguistic heritage.
The Unicode Consortium thanks comprigo for their support!
As a product- and price comparison website, comprigo redefines the assets of online shopping by helping our customers make the best possible purchase decision. With our permanent adoption we want to make a statement and support the unique visual semantics of Unicode Consortium in a world where visual communication becomes more and more important. As a globally active software company, we want to support Unicode by not just preserving linguistic heritage, but also by enabling intercultural communication. The comprigo Moneybag is a perfect representation of what users gain from using our services: purchase the best product for the best price. — comprigo
All sponsors are listed on Sponsors of Adopted Characters. More than 128,000 other characters are available for adoption — see Adopt a Character.
Monday, September 25, 2017
Proposed Draft UTR #53, Unicode Arabic Mark Ordering Algorithm Now Available for Public Review
The Unicode Consortium has released Proposed Draft Unicode Technical Report #53, Unicode Arabic Mark Ordering Algorithm. This UTR describes an algorithm for determining correct rendering of Arabic combining mark sequences.
The combining classes of Arabic combining characters in Unicode are a mixture of special classes for specific marks plus two more generalized classes for all the other marks. For many years this has resulted in inconsistent rendering for sequences with multiple combining marks such as:

The algorithm described in this UTR provides a method to reorder Arabic combining marks in order to accomplish the following goals:
For information about how to discuss this Public Review Issue and how to supply formal feedback, please see the PRI #359 page.
The combining classes of Arabic combining characters in Unicode are a mixture of special classes for specific marks plus two more generalized classes for all the other marks. For many years this has resulted in inconsistent rendering for sequences with multiple combining marks such as:
The algorithm described in this UTR provides a method to reorder Arabic combining marks in order to accomplish the following goals:
- The inside-out rendering rule will display combining marks in the expected visual order.
- Ensure identical display of canonically equivalent sequences.
- Provide a mechanism for overriding the display order in exceptional cases.
For information about how to discuss this Public Review Issue and how to supply formal feedback, please see the PRI #359 page.
Monday, September 18, 2017
Unicode CLDR 32α available for testing
 The alpha version of Unicode CLDR 32 is available for testing. The alpha period lasts until the beta release on September 27, which will include updates to the LDML spec. The final release is expected on October 19.
The alpha version of Unicode CLDR 32 is available for testing. The alpha period lasts until the beta release on September 27, which will include updates to the LDML spec. The final release is expected on October 19.CLDR 32 provides an update to the key building blocks for software supporting the world's languages. This data is used by all major software systems for their software internationalization and localization, adapting software to the conventions of different languages for such common software tasks.
CLDR 32 included a Survey Tool data collection phase, with a resulting significant increase in data size, especially for emoji names/annotations and geographic subdivision names. Other enhancements include rule-based number formats for additional languages, a new “disjunctive” list style (a, b, or c), and fixes for Chinese collation and transliteration. The draft release page at http://cldr.unicode.org/index/downloads/cldr-32 lists the major features, and has pointers to the newest data and charts. It will be fleshed out over the coming weeks with more details, migration issues, known problems, and so on. Particularly useful for review are:
- Delta Charts - the data that changed during the release
-
By-Type Charts - a side-by-side comparison of data from different locales
- Annotation Charts - new emoji names and keywords
-
Territory Subdivisions
Subscribe to:
Posts (Atom)

