Non-profit consortium invites public to adopt any emoji, letter or symbol as fun, meaningful gifts that fund research and coding needed to support minority languages

MOUNTAIN VIEW, Calif.—(BUSINESS WIRE)—Unicode Consortium, the 501(c)(3) non-profit that standardizes the way computers represent text in all languages – including emoji characters – today announced its Adopt-a-Character campaign. The new program is an opportunity to adopt and dedicate an emoji, letter or any symbol on the keyboard to help Unicode’s important work of supporting the world’s languages in digital form. Adoption options are available at $100, $1,000 and $5,000 levels and make meaningful and fun gifts for the holidays or any occasion. Adoption donations are tax deductible in the U.S.
Funds raised will be used to support Unicode’s core mission of developing and extending the necessary standards, data and software to support the world’s living languages. Unicode works with linguists, experts, cultural leaders and technologists to create coding standards to support minority languages in digital form.
“Beyond our work standardizing emoji, Unicode is tackling some big challenges that might surprise many people,” said Mark Davis, co-founder and president of the Unicode Consortium and an internationalization expert at Google. “The vast majority of the world’s living languages, close to 98 percent, are ‘digitally disadvantaged’ – meaning they are not supported on the most popular devices, operating systems, browsers and mobile applications. For example, only a handful of African languages have adequate digital support. The funds from our new Adopt-a-Character campaign will help us continue the important standardization work that is best done by a neutral organization like Unicode.”
Ensuring Digital Vitality, from Cherokee to N’Ko
So far, Unicode’s resources have been focused on the most-prominent scripts and languages of the world. Gathering information for less-prominent scripts and languages – such as Berber, Balinese, Cherokee, Javanese, N’Ko, Pahawh Hmong and Kashmiri – is often more difficult, requiring travel, research, engineering resources and software tooling.
Just 15 years ago, Cherokee was not available digitally and now as a result of Unicode’s work it can be found on computers, mobile devices such as the iPhone and iPad, and on Gmail. Because of Unicode’s work standardizing N’Ko – a script used to write a number of the West African Mande languages, with a population of over 20 million people – publishers are now able to modernize their operations, print in multiple locations and reach a broader audience.
“The Internet has made us all more acutely aware of how small our world is and how rich the creations of its inhabitants are,” said Greg Welch, a Unicode board member and Senior Director, Strategic Marketing, Mobile Client Platforms at Intel. “As we become a more connected and paperless global society, we cannot leave minority and digitally disadvantaged languages behind. It’s vital to ensure that the text on which a culture’s propagation depends makes it across the digital divide.”
How to Adopt-a-Character
More information about Adopt-a-Character can be found at
http://unicode.org/consortium/adopt-a-character.html
About Unicode Consortium
The Unicode Consortium’s mission is to lay a solid foundation for digital support of the world’s languages. If you've used any computer or smartphone, then you're using Unicode and have benefited from the consortium’s work. The consortium – whose members include companies such as Adobe, Apple, Facebook, Google, IBM, Microsoft and more – is a 501(c)(3) non-profit that emerged from the technology industry’s effort to standardize the way computers represent text (including emoji) in all languages – from English to Chinese to Zulu – across different devices and operating systems. The group operates largely as a volunteer organization that is funded by membership fees and donations. A full list of members is on
http://unicode.org/consortium/members.html
 The Unicode Consortium announced today it is updating the Unicode emoji charts with the following major changes:
The Unicode Consortium announced today it is updating the Unicode emoji charts with the following major changes: 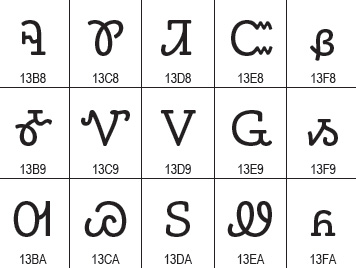
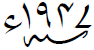 The Unicode Technical Committee is seeking feedback on a proposal to define a new character property for the class of prepended concatenation marks, also referred to as prefixed format control characters or, more generically, as subtending marks. Characters in that class include U+0600 ARABIC NUMBER SIGN and U+06DD ARABIC END OF AYAH. The new property, named Prepended_Concatenation_Mark and targeted for Unicode 9.0, would provide a mechanism to handle subtending marks collectively via properties rather than by hardcoded enumeration. A detailed description of the issue and how to provide feedback are given in
The Unicode Technical Committee is seeking feedback on a proposal to define a new character property for the class of prepended concatenation marks, also referred to as prefixed format control characters or, more generically, as subtending marks. Characters in that class include U+0600 ARABIC NUMBER SIGN and U+06DD ARABIC END OF AYAH. The new property, named Prepended_Concatenation_Mark and targeted for Unicode 9.0, would provide a mechanism to handle subtending marks collectively via properties rather than by hardcoded enumeration. A detailed description of the issue and how to provide feedback are given in  A new revision of
A new revision of  The Unicode 8.0 core specification is now available in paperback book form.
The Unicode 8.0 core specification is now available in paperback book form. The Unicode Consortium has accepted 7 new emoji characters as candidates for Unicode 9.0, scheduled for release in mid-2016. This makes a total of
The Unicode Consortium has accepted 7 new emoji characters as candidates for Unicode 9.0, scheduled for release in mid-2016. This makes a total of  New information about emoji is available on
New information about emoji is available on  Unicode Standard Annex #31, Unicode Identifier and Pattern Syntax, will be updated for Unicode 9.0. The
Unicode Standard Annex #31, Unicode Identifier and Pattern Syntax, will be updated for Unicode 9.0. The 
 Unicode Standard Annex #29, Unicode Text Segmentation, will be updated for Unicode 9.0. A
Unicode Standard Annex #29, Unicode Text Segmentation, will be updated for Unicode 9.0. A 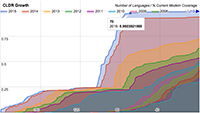
 The Unicode Consortium is pleased to announce that
The Unicode Consortium is pleased to announce that  The Unicode Consortium is pleased to announce that Emoji One has joined as a supporting member. Emoji One is a small, independent group of emoji developers providing an open source emoji set for digital and non-digital use worldwide.
The Unicode Consortium is pleased to announce that Emoji One has joined as a supporting member. Emoji One is a small, independent group of emoji developers providing an open source emoji set for digital and non-digital use worldwide. The Henry Luce Foundation has made a grant to the Unicode Consortium in
support of three meetings between Unicode specialists, experts, and user
communities in Mongolia and China. The meetings, which will take place from
2015 to 2017, will discuss encoding issues relating to specific scripts in
the region, such as Mongolian Square and Soyombo. The goal of the meetings
is to move the scripts forward in the encoding process, so scholars and the
relevant user communities will eventually be able to create, send, and
search materials in these scripts electronically. The project is headed by
Dr. Deborah Anderson, Technical Director of the Consortium, and Project
Leader of the UC Berkeley Script Encoding Initiative.
The Henry Luce Foundation has made a grant to the Unicode Consortium in
support of three meetings between Unicode specialists, experts, and user
communities in Mongolia and China. The meetings, which will take place from
2015 to 2017, will discuss encoding issues relating to specific scripts in
the region, such as Mongolian Square and Soyombo. The goal of the meetings
is to move the scripts forward in the encoding process, so scholars and the
relevant user communities will eventually be able to create, send, and
search materials in these scripts electronically. The project is headed by
Dr. Deborah Anderson, Technical Director of the Consortium, and Project
Leader of the UC Berkeley Script Encoding Initiative.





 →
→ 






































