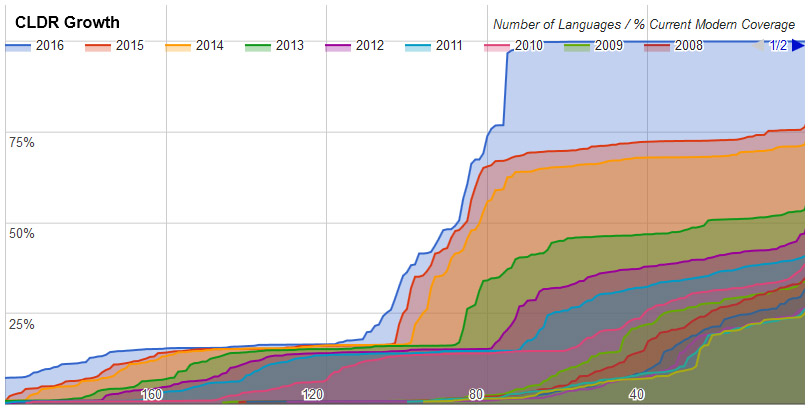
ICU 58 provides full support for the recent Unicode 9.0 release with 7,500 new characters and many property improvements. It covers the Unicode 9.0 emoji characters — plus the latest draft version of Emoji 4.0 — for a total of 2,444 emoji characters and sequences, including the new ZWJ sequences for gendered professions; ICU word & line breaking is updated for Emoji 4.0. ICU 58 incorporates the latest version 30 of Unicode CLDR locale data with a significant increase in data coverage.
There are a number of new APIs, including ones for measurement system unit display names (such as “acre” or “Hektar” in 80 languages), and improvements in performance and robustness. For Java, the unit tests are converted to JUnit, for easier and faster integration into test suites.
For details please see http://site.icu-project.org/download/58