KEYNOTE PRESENTER ANNOUNCED!
 |

Dr. Mark Davis
Unicode President and
Co-Founder |
The Unicode Consortium has announced that its president and co-founder, Dr.
Mark Davis, will deliver the keynote address at this year’s
Internationalization & Unicode Conference (IUC), November 3-5. Dr. Davis’s talk,
Emoji: Past, Present, and Future, will discuss where emoji came from, why they have gotten so
popular, where they’ve gone wrong, and what the future will bring.
“Emoji became very popular in Japan right after they were introduced in
1999,” said Dr. Davis. “Once they were added to Unicode in 2010, they became
popular worldwide, used in modern mobile phones, texting systems, email, and so
on. For example, there were some 6,000 articles on emoji in the month after
Unicode 7.0 released, according to Google News.”
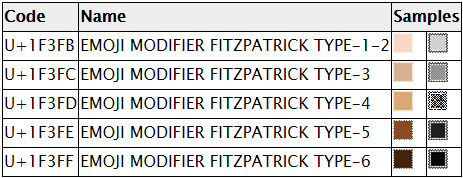
Dr. Davis will explore the history of emoji, how they came to be added to Unicode, how they are used in practice, and some of the deficiencies that people see. For example, what about the lack of human diversity and why isn’t there a hot dog emoji? He will then illuminate some of the future additions from Unicode and answer some of the most common questions about emoji.
IUC is the premier event covering the latest in industry standards and best
practices for bringing software and Web applications to worldwide markets.
Subject areas include the global impact, programming practices, fonts and
rendering, and mobile computing. For the eighth year, Adobe will be sponsoring
the conference.
To view the full IUC agenda and to register, visit
www.unicodeconference.org.


 The Unicode Consortium has accepted 37 new emoji characters as
candidates for Unicode 8.0, scheduled for mid-2015. These are candidates—not yet
finalized—so some may not appear in the release.
The Unicode Consortium has accepted 37 new emoji characters as
candidates for Unicode 8.0, scheduled for mid-2015. These are candidates—not yet
finalized—so some may not appear in the release. The Unicode Consortium has released the draft “
The Unicode Consortium has released the draft “