The IUC 44 Program Committee invites you
to submit your session, tutorial, or panel abstracts for
the 44th Internationalization &
Unicode® Conference (IUC 44) in Santa Clara,
California, October 14-16, 2020.
Join other industry leaders as they map
the future of internationalization, ignite new ideas,
and showcase the latest technologies and best practices
for creating, managing, and testing global, web, and
multilingual software solutions. Be a leader. Direct the
future of multilingual text and software
internationalization!
Submission types could include case
studies, best practices, innovative technology, or
evolving standards, to name a few. In addition,
understanding the design of a development platform is
often critical to implementing best practices in
applications. The Internationalization and Unicode
Conference seeks to offer technical tutorials on the
internationalization capabilities and architecture of
development platforms, including Mobile, Desktop, Cloud,
and Virtual Operating Systems, Social Network Platforms,
and Machine Translation and Machine Learning Systems.
Please
submit your proposals for presentations or tutorials
by
Friday, March 6, 2020.
The Program
Committee will notify authors by
Friday, April 3, 2020.
Speaker agreements and materials such as photos, bios
and final presentation abstracts will be required from
selected presenters by Friday,
April 17, 2020.
Tutorial
Presenters receive complimentary conference
registration, and two nights lodging, while
Session Presenters receive
a fifty percent conference discount and two nights
lodging.
Please visit our website to view examples of content from
past conferences.
About The Unicode Consortium
The
Unicode®Consortium is a non-profit organization founded to develop,
extend and promote use of the Unicode Standard and related
globalization standards.
The membership of the consortium represents a broad spectrum of corporations and organizations, many in the computer and information processing industry. Members include: Adobe, Apple, Emojipedia, Facebook, Google, Government of Bangladesh, Government of India, Huawei, IBM, Microsoft, Monotype Imaging, Netflix, Sultanate of Oman MARA, Oracle, SAP, Tamil Virtual University, The University of California (Berkeley), plus well over a hundred Associate, Liaison, and Individual members.
For more information, please contact the
Unicode Consortium.
About the Event Producer
OMG® is the Event Producer for the
Internationalization & Unicode Conferences. OMG is an international,
open membership, not-for-profit computer industry standards
consortium. OMG Task Forces develop enterprise integration standards
for a wide range of technologies and an even wider range of
industries. OMG's modeling standards, including the Unified Modeling
Language™ (UML®) and Model Driven Architecture® (MDA®), enable
powerful visual design, execution and maintenance of software and
other processes, including IT Systems Modeling and Business Process
Management. OMG's middleware standards and profiles are based on the
Common Object Request Broker Architecture (CORBA®) and support a
wide variety of industries. OMG has offices at 109 Highland Avenue,
Needham, MA 02494 USA. This email may be considered to be commercial
email, an advertisement or a solicitation.
For more information about OMG, visit us online at
https://www.omg.org.
 The
2020 Unicode Bulldog Award recognizes Kristi Lee for her significant contributions to
the work of the Unicode Consortium’s CLDR Technical Committee. Upon joining
the CLDR committee as Microsoft’s representative, Kristi quickly focused on improving
CLDR development and release processes, enabling the CLDR team to work far more
efficiently and effectively. This has improved the functionality of the CLDR Survey
Tool, and thus better serves the users of CLDR releases. Among many
other improvements, she instituted and organized periodic CLDR
face-to-face meetings where the team can focus on strategic planning. Through
all these efforts, Kristi has brought strong leadership to enable more
streamlined development and a better focus on future directions.
The
2020 Unicode Bulldog Award recognizes Kristi Lee for her significant contributions to
the work of the Unicode Consortium’s CLDR Technical Committee. Upon joining
the CLDR committee as Microsoft’s representative, Kristi quickly focused on improving
CLDR development and release processes, enabling the CLDR team to work far more
efficiently and effectively. This has improved the functionality of the CLDR Survey
Tool, and thus better serves the users of CLDR releases. Among many
other improvements, she instituted and organized periodic CLDR
face-to-face meetings where the team can focus on strategic planning. Through
all these efforts, Kristi has brought strong leadership to enable more
streamlined development and a better focus on future directions.![[badge]](https://www.unicode.org/announcements/ynh-infinity.png)
![[CLDR v38 image]](https://www.unicode.org/announcements/cldr38-annc.png)
![[badge]](http://www.unicode.org/announcements/ynh-infinity.png)
![[beta image]](https://www.unicode.org/announcements/large-beta-green.png)


![[badge]](http://www.unicode.org/announcements/ynh-flaming-heart.png)



![[badge]](http://www.unicode.org/announcements/ynh-baguette.png)
 Regular expressions are a powerful tool for using patterns to search and modify text, and are vital in many programs, programming languages, databases, and
spreadsheets.
Regular expressions are a powerful tool for using patterns to search and modify text, and are vital in many programs, programming languages, databases, and
spreadsheets.![[badge]](http://www.unicode.org/announcements/ynh-1fab4-potted-plant.png)
![[U13 cover image]](https://www.unicode.org/announcements/annc-v13-cover-huijun-shan.jpg "[U13 cover image]") The Unicode 13.0 core specification is now available in paperback book form with a new, original cover design by Huijun Shan. This edition consists of a pair of modestly priced print-on-demand volumes containing the complete text of the core specification of Version 13.0 of the Unicode Standard.
The Unicode 13.0 core specification is now available in paperback book form with a new, original cover design by Huijun Shan. This edition consists of a pair of modestly priced print-on-demand volumes containing the complete text of the core specification of Version 13.0 of the Unicode Standard.![[badge]](https://www.unicode.org/announcements/ynh-1fab4-potted-plant.png)
![[IVD image]](https://www.unicode.org/announcements/msarg-pri418-example.gif "[IVD image]") The Unicode Consortium has posted a new issue for public review and comment.
The Unicode Consortium has posted a new issue for public review and comment.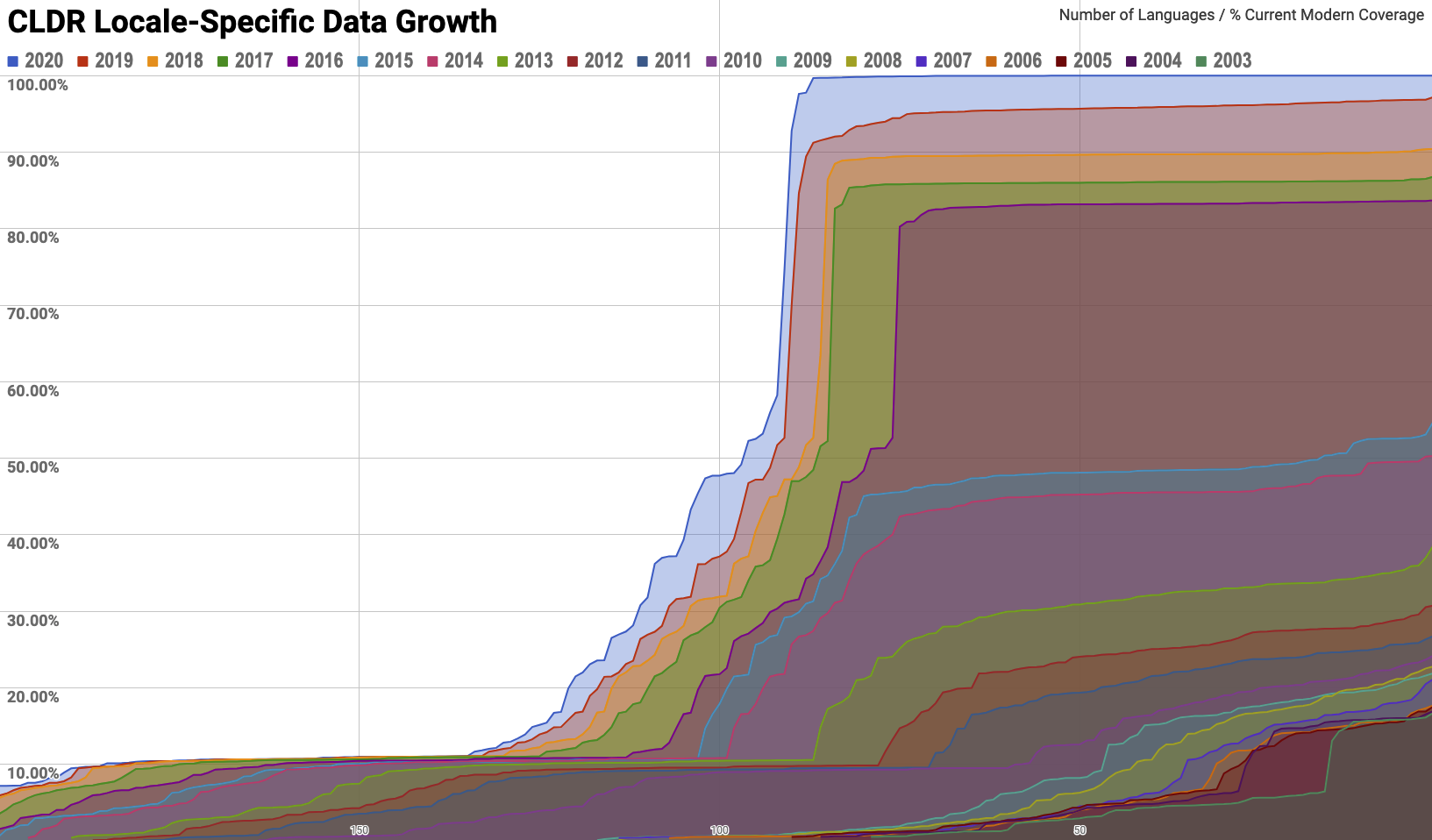
![[chart image]](http://unicode.org/announcements/annc-v13-fbb2-1fbc6.jpg "[chart image]") Version 13.0 of the Unicode Standard is now available, including the core specification, annexes, and data files. This version adds 5,390 characters, for a total of 143,859 characters. These additions include four new scripts, for a total of 154 scripts, as well as 55 new emoji characters.
Version 13.0 of the Unicode Standard is now available, including the core specification, annexes, and data files. This version adds 5,390 characters, for a total of 143,859 characters. These additions include four new scripts, for a total of 154 scripts, as well as 55 new emoji characters.
![[art by Du Lilyu]](http://www.unicode.org/announcements/annc-v13-lilyu-du.jpg "[art by Du Lilyu]")
![[art by Saagar Setu]](http://www.unicode.org/announcements/annc-v13-saagar-setu.jpg "[art by Saagar Setu]")









![[badge]](http://www.unicode.org/announcements/ynh-wood-log.png)
![[Mayan Image]](http://www.unicode.org/announcements/mayan-annc.jpg)
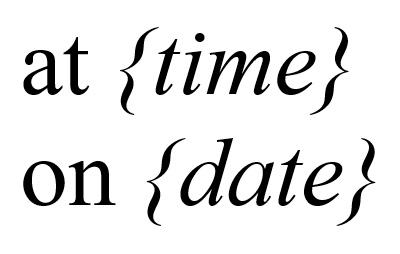 One of the challenges in adapting programs to work with different languages is message
formatting. This is the process of formatting and inserting data values into
messages in the user’s language. For example, “The package will arrive at {time}
on {date}” could be translated into German as “Das Paket wird am {date} um
{time} geliefert”, and the particular {time} and {date} variables would be
automatically formatted for German, and inserted in the right places.
One of the challenges in adapting programs to work with different languages is message
formatting. This is the process of formatting and inserting data values into
messages in the user’s language. For example, “The package will arrive at {time}
on {date}” could be translated into German as “Das Paket wird am {date} um
{time} geliefert”, and the particular {time} and {date} variables would be
automatically formatted for German, and inserted in the right places.
