Unicode CLDR 30 provides an update to the key building blocks for software
supporting the world’s languages. This data is used by all
major software
systems for their software internationalization and localization, adapting
software to the conventions of different languages for such common software
tasks. The following summarizes the main improvements in the release.
- Unicode support is updated to 9.0, including updated Unihan readings for
the pinyin collation and Han-Latin transforms, and support for new script
codes and number systems.
- The set of language codes for translation has been updated, with a
significant increase in the total number of translated language names.
- Substantial new data has been added for likely subtags (e.g., to get the
main script for each language).
- New data items have been added to support relative times such as “3
Fridays ago” or “this hour”.
- New draft format and preference structure has been added to support week
designations such as “the week of August 10” or “week 3 of March”.
- New <characterlabels> data can be used to generate labels for groups of
related characters in character pickers.
- The structure for emoji annotations has been revised, and the data has
been significantly updated. The emoji collation has been updated, and data
is added for improved segmentation behavior. Added a specification for
synthesizing ZWJ sequence names.
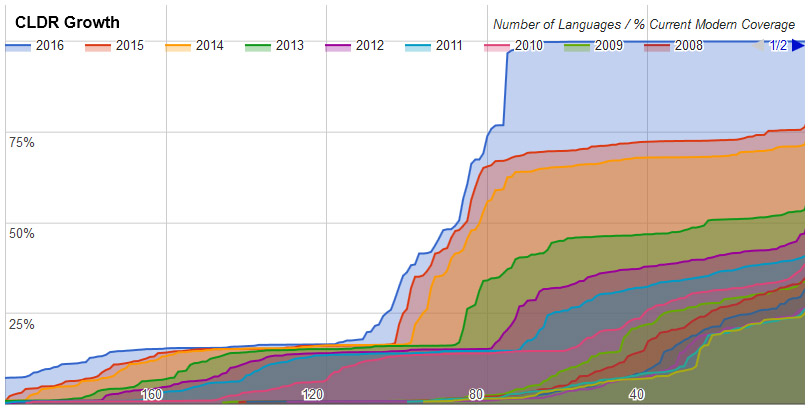
- The CLDR 30 Survey Tool data collection resulted in a net increase in
data items of about 9.2%, with an additional 5.9% of items changed.
For further details and links to documentation, see the
CLDR Release Notes

